想要让深度学习系统走向大街小巷、走进千家万户,就要在算法研发阶段给出系统的鲁棒性检验。对于图像对抗性攻击的讨论正是如火如荼,攻防双方都是妙手频出的状态。例如,来自 MIT 和 UC Berkeley 的两位博士生,Anish Athalye 和 Nicholas Carlini 就接连攻破了 7 篇 ICLR 2018 接收的对抗防御文章,指出,你们的防御策略不过都是基于「混淆梯度」(obfuscated gradient)现象的「虚假安全感」。虽然 Ian Goodfellow 回应称「混淆梯度」不过是之前「梯度遮挡」(gradient masking)的老调重弹,而且声称「遍历了 ICLR 8 篇对抗防御论文」的作者是不是漏掉了我参与的 ICLR 入选论文《Ensemble Adversarial Training: Attacks and Defenses》呀?但 Ian 的回击仍然不妨碍 Athalye 和 Carlini 成为名噪一时的攻方代表。
图像领域的攻击防御如此热闹,是因为图像识别的应用场景直指安防、自动驾驶这类关乎生命安全的方向,而当 2017 年,当国内外业界里,无论是雄踞一方的巨头还是崭露头角的新秀,都争先恐后地发布「智能音箱」,进而用跳楼价在家居语音入口这个还远不成气候的领域里圈地盘的时候,学界对于语音对抗性攻击的关注,也终于在视觉之后水涨船高了。
比如,上文中提到的「拳打 ICLR」的博士生之一,UC Berkeley 的 Nicholas Carlini 就与其导师一起,在《Audio Adversarial Examples: Targeted Attacks on Speech-to-Text》一文中给出了对 Mozilla 实现的百度 DeepSpeech 论文的一个白箱、定向、需要直接输入的攻击。给定任意一个波形,甚至不必须是语音,音乐乃至无声都可以,就能用优化的办法生成一个 99.9% 相似的、但是会被语音识别系统转写成完全不同的另一段话的新波形。
本文接下来,就将沿着这篇工作展开,简单聊聊对抗样本的分类,然后验证一下作者提供的对抗样本的攻击效果。
首先聊聊对抗样本的分类。
「白箱、定向、需要直接输入」这三个修饰「攻击」的形容词,其实都在从攻击的力度层面对对抗样本进行分类。阅读对抗样本相关工作的时候,我们首先可以问这样三个问题:
1 对抗样本的制造过程中,是否拥有模型结构及参数的知识?
如果答案是肯定的,那么攻击是「白箱」攻击。如果答案是否定的,则为「黑箱」攻击。
了解模型结构和参数,换言之了解模型的预测行程的过程,就能够有的放矢地进行对抗样本的构建,这无疑是更容易的,因此最先成功的以及当前大部分的对抗样本都是白箱攻击。
是否有成功的黑箱攻击呢?在图像领域,有,Ian Goodfellow 在 2016 年参与的一篇文章,《Practical Black-Box Attacks against Machine Learning》,就给出了一个「利用原模型生成样本及标签,创建合成训练集(synthetic dataset)、利用训练集建立原模型的替代网络(substitute network)、再利用替代网络优化创建对抗样本」的解决方案。
但是在语音领域,尚没有成功的黑箱攻击。本文就是一个白箱攻击,攻击的对象是 Mozilla 去年年底开源的语音识别模型 DeepSpeech 0.1.0 版本。DeepSpeech(GitHub: https://github.com/mozilla/DeepSpeech)是对百度硅谷 AI 实验室(SVAIL)2014 年的论文《Deep Speech: Scaling up end-to-end speech recognition》的一个 TensorFlow 实现,在 LibriSpeech clean test corpus 上达到了 6.0% 的词错率(WER)。
插一句,看到这里还是很唏嘘的,百度是最早站在深度学习研究一线的 BAT 了,这篇文章的作者列表里赫然有当年的百度 AI 研究总负责人吴恩达和硅谷 AI 实验室总负责人 Adam Coates。然而去年一年里,吴恩达、Adam Coates 以及吴恩达的继任者林元庆已经先后离开百度,百度的 AI 研究力量,也随着李彦宏「从没说过 All in AI」的宣言,散落天涯了。
2 对抗样本能保证模型错误的类型吗?
如果答案是肯定的,那么进行的是定向(targeted)攻击,否则则是非定向(untargeted)攻击。
具体一点解释,对于非定向攻击来说,能让一个区分动物的模型把猫识别成任何其他动物,都算是攻击成功。而对于定向攻击来说,构建对抗样本的时候的目标要更加明确:例如,目标是让模型把猫识别成狗,那么如果模型把猫识别成了兔子,仍然要说定向攻击是失败的。
本文是一个定向攻击,如下图所示,给定一个声波 x,可以造出一个干扰项 δ,让 x+δ 能够被机器识别成指定的、与 x 不同的标签。
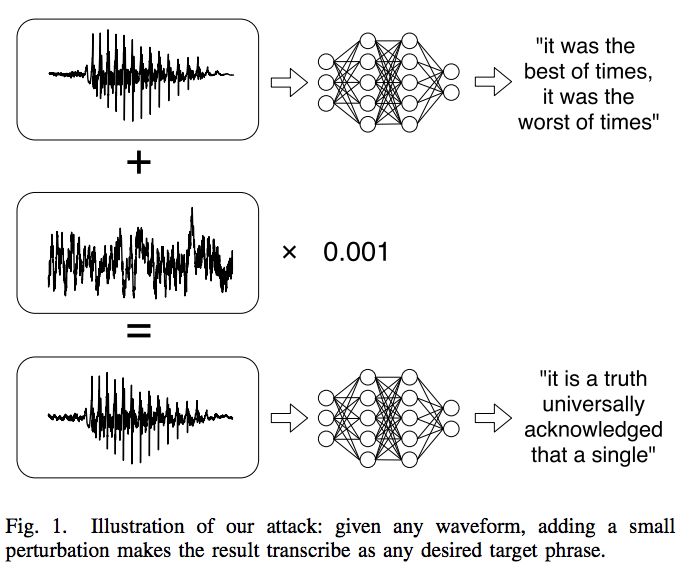
不过!Mozilla DeepSpeech 在今年 1 月底更新了 v0.1.1,进行了一些依赖项调整,重新训练了参数,但并没有改动主要结构。然而在后文,当我用新版本测试作者给出的对抗样本的时候,发现攻击样本已经不能「指哪儿打哪儿」地篡改语音内容了,而是会输出一段乱码,换言之,一旦白箱设定稍有收缩、参数改动,定向攻击就会退化成非定向攻击。
3 对抗样本可以进入现实场景吗?
这个问题听起来非常宽泛,但其实是衡量对抗样本威胁性的一个重要指标。
如果答案是否定的,样本需要直接作为输入进入模型,那么其威胁性是有限的。例如本文中的音频样本,只能直接以 WAV 格式交给模型,才能有攻击效果;如果用播放器播放再用麦克收音,攻击就完全失效了——不只是从定向攻击退化成非定向攻击,而是完全没有攻击效果。
如果答案是肯定的,那么语音攻击的样本就可以在不知不觉中唤醒你的语音助手然后进行特定的操作。去年浙江大学的《DolphinAttack: Inaudible Voice Commands》,就利用了谐波以及麦克风和人耳接受声音频率的范围不同,实现在人感知不到的情形下通过麦克风唤醒 Siri、Google Assistant 和 Alexa 等系统并执行相应语音命令的操作。当然,考虑到这类攻击必须利用专业设备、设备距离麦克风不超过 1.5 米,以及供应商可以在系统端通过设置允许频率范围进行防御等等特点,这类攻击真实的「威胁性」并没有那么高,但是它确实是可以进入现实场景的攻击。
图像领域里进入现实场景的样本攻击就更多了,有可以打印出来放在待识别物体周围扰乱分类的贴纸,也有哪怕不是直接进入模型,而是被摄像机捕捉,也仍然能进行攻击的像素改变技术。
总之,白箱还是黑箱、是否定向、是否可以进入现实场景,是根据攻击的威胁性对对抗样本进行分类的三个相对重要的角度,除此之外,也有是否对压缩鲁棒、是否可迁移等其他衡量标准,大家可以阅读论文做详细了解。
解释完一连串的形容词之后来看看对抗样本的测试攻击效果。
作者在个人网站上(https://nicholas.carlini.com/code/audio_adversarial_examples/)公布了一些对抗样本的样例。人耳听起来几乎一样的一段语音,(听起来都是一个带着咖喱口音的大叔在说「that day the merchant gave the boy permission to build the display」,只不过后两个样本中背景里有轻微的杂音)会被系统分别识别为三句截然不同的话。

我利用 Google Colab 薅了一点点 GPU 资源测试了下 DeepSpeech 对攻击的反应。关于 Google Colab 的用法,可以参考之心之前的文章:Colab详细使用教程。
首先把上面三个音频文件放在 Google Drive 上,并通过右键选择「Get Sharable Link」拿到对应的 id(链接中 id= 后面的部分)。
然后开一个 Colab Notebook,在选项栏 Edit ==》Notebook Setting 里选择 GPU。
安装 DeepSpeech 包:
!pip install deepspeech-gpu
下载模型 0.1.0 版本:
注意,最新版是 0.1.1,作者用的版本是 0.1.0,不要下错。
!wget -O - https://github.com/mozilla/DeepSpeech/releases/download/v0.1.0/deepspeech-0.1.0-models.tar.gz | tar xvfz -
验证模型文件的 MD5 sum:
进行授权登录以加载数据:
!pip install -U -q PyDrive加载数据:
运行预训练好的模型进行推断:
注意,不同于 github 上给的命令,参数顺序是:模型、音频文件、字母表、lm(非必须)、trie(非必须)
!deepspeech models/output_graph.pb 音频文件名.wav models/alphabet.txt models/lm.binary models/trie参数说明:
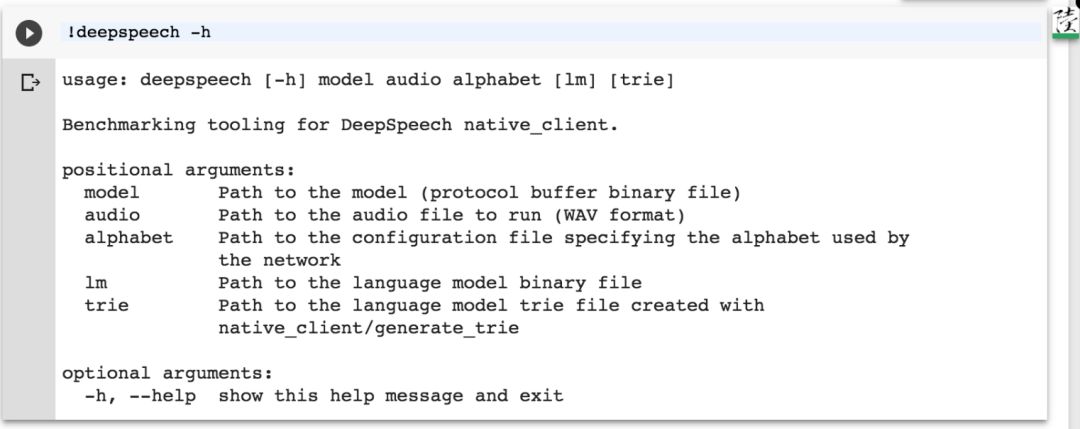
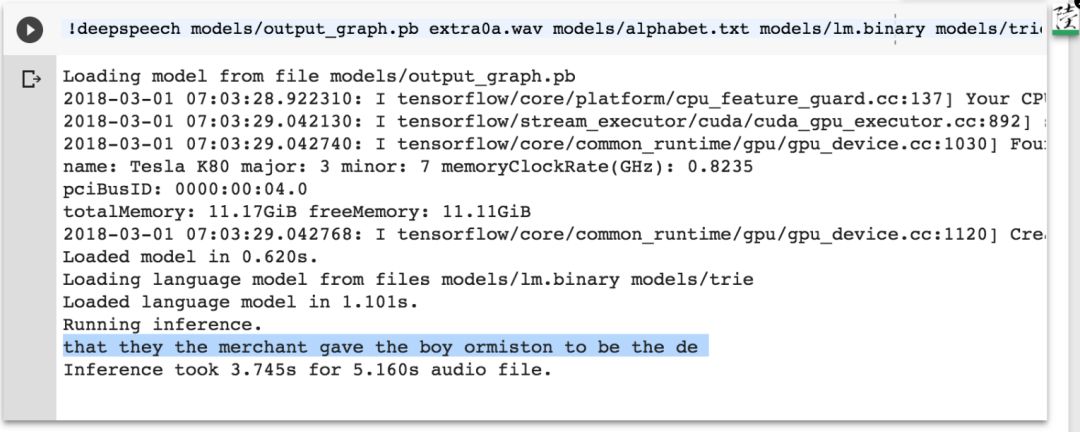
extra0a.wav 识别结果:还是有一点不准的。

extra0b.wav 识别结果:
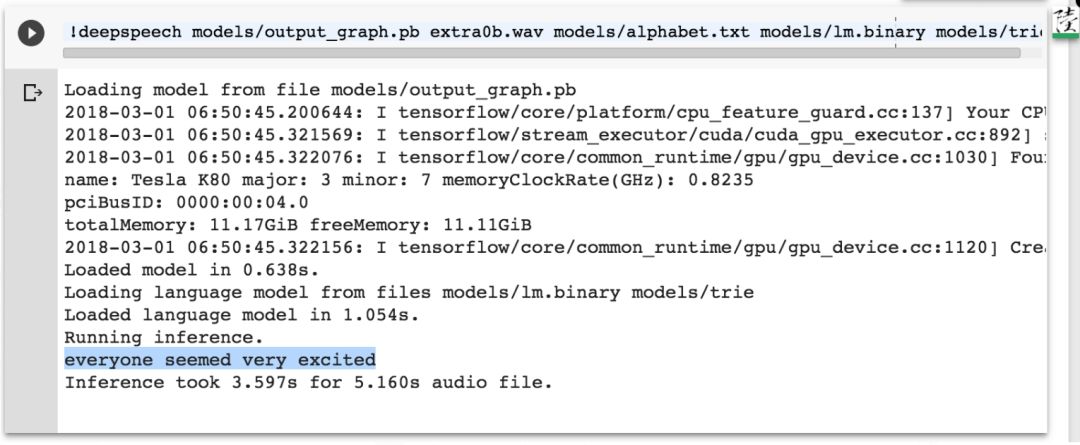
extra0c.wav 识别结果:
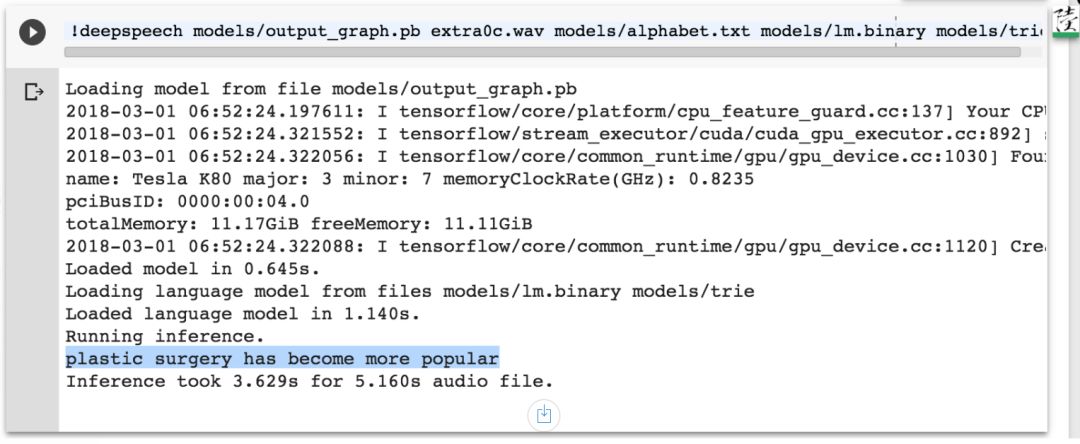
复现了对抗结果。
接下来我们试验一下 v0.1.1 对对抗样本的反应。
新版本是一个针对这篇论文进行调整的模型吗?版本的主要改动说明中并未对此进行说明,但是,版本的提交者确实是知晓这篇论文的存在的,他提出了一个至今仍然开放的 issue(GitHub: https://github.com/mozilla/DeepSpeech/issues/1179),但是并没有人回应。
让我们看看新版本的效果:
extra0a.wav 识别结果:分割好了一点。
extra0b.wav 识别结果:乱码了。
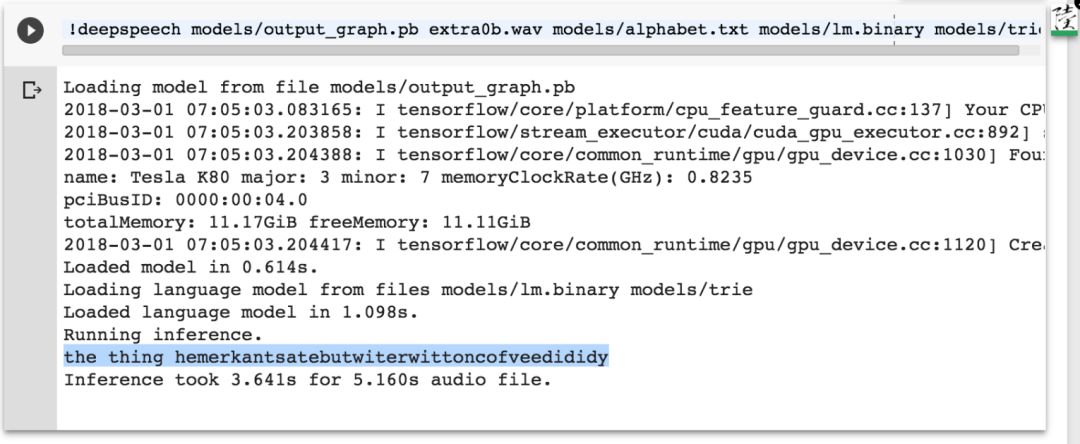
extra0c.wav 识别结果:仍然是乱码。
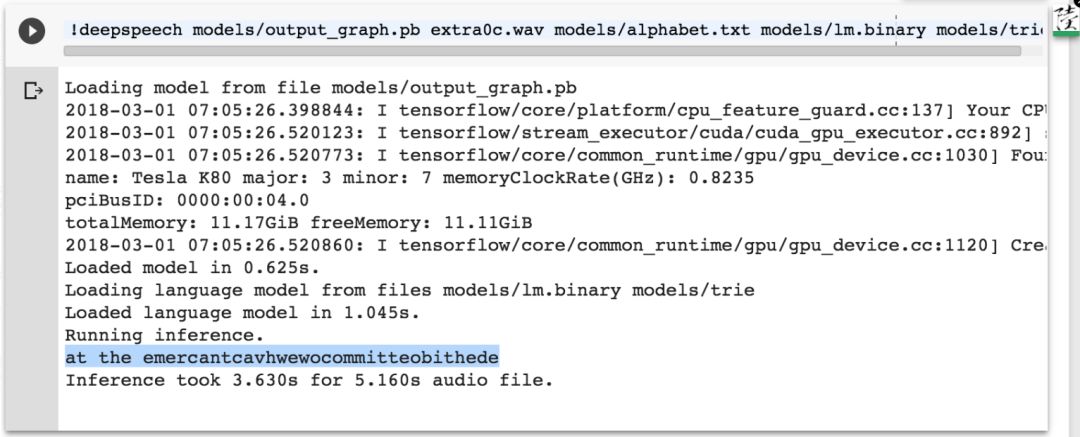
模型结构未变,参数变了,对抗样本就从定向变成非定向了。
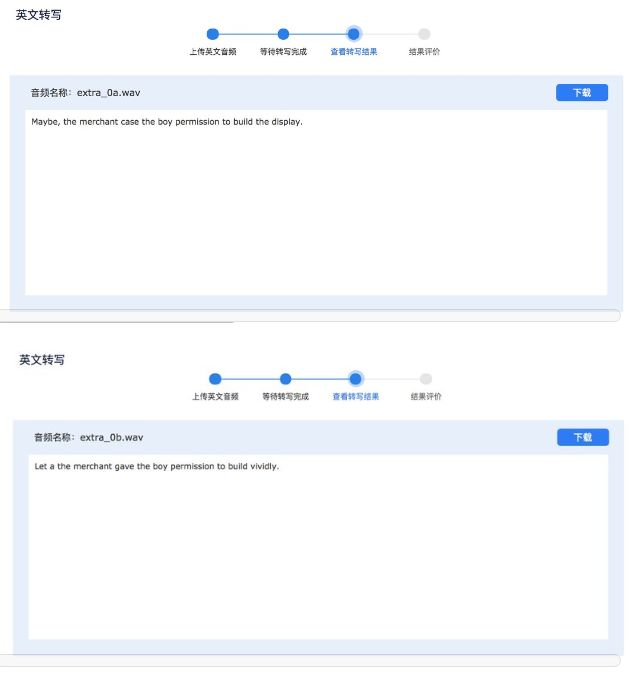
出于好奇,我还拿讯飞听见的英文听写功能(beta 版)测试了一下:对抗并没有效果,而且识别效果也还不错。
总体而言,作者能够对一个固定结构、固定参数的模型实现有效的白箱定向攻击,但是这种攻击是不可迁移、不可扩展的。文章的贡献在于在语音方面开始了对「定向」的探索。因为不同于自动驾驶等视觉场景,对于现阶段的语音模型与系统来说,非定向攻击并没有太大的威胁性。在自动驾驶场景里,一个能够让「禁行」、「急转弯」路牌无法被准确识别的非定向攻击,就会造成严重的后果。但是在语音系统中,非定向攻击造成的后果不外乎「语音助手变成了语音废柴」,并不会威胁用户的隐私、财产或者生命安全,从「人工智障时代」一路走来的用户对这种程度的漏洞还是有相当的宽容度的。因此,能够对语音系统产生影响,推动其进步的对抗样本必然是以定向为基础的。我们也期望有更多以定向为基础,穿透语音识别系统中不同模型的集成,更加深入语音识别本质的,对抗样本攻击的出现。




